Table of Contents¶
1 An example of a small Single-Player simulation
1.1 Creating the problem
1.1.1 Parameters for the simulation
1.1.2 Some MAB problem with Bernoulli arms
1.1.3 Some RL algorithms
1.2 Creating the Evaluator object
1.3 Solving the problem
1.4 Plotting the results
1.4.1 First problem
1.4.2 Second problem
1.4.3 Third problem
An example of a small Single-Player simulation¶
First, be sure to be in the main folder, or to have SMPyBandits installed, and import Evaluator from Environment package:
[2]:
!pip install SMPyBandits watermark
%load_ext watermark
%watermark -v -m -p SMPyBandits -a "Lilian Besson"
Requirement already satisfied: SMPyBandits in ./venv3/lib/python3.6/site-packages (0.9.4)
Collecting watermark
Using cached https://files.pythonhosted.org/packages/81/c8/9d3dd05a91bdbda03e24e52870b653c9345a0461294a7290f321bba18fad/watermark-1.7.0-py3-none-any.whl
Requirement already satisfied: numpy in ./venv3/lib/python3.6/site-packages (from SMPyBandits) (1.15.4)
Requirement already satisfied: matplotlib>=2 in ./venv3/lib/python3.6/site-packages (from SMPyBandits) (3.0.2)
Requirement already satisfied: scikit-learn in ./venv3/lib/python3.6/site-packages (from SMPyBandits) (0.20.0)
Requirement already satisfied: scikit-optimize in ./venv3/lib/python3.6/site-packages (from SMPyBandits) (0.5.2)
Requirement already satisfied: seaborn in ./venv3/lib/python3.6/site-packages (from SMPyBandits) (0.9.0)
Requirement already satisfied: joblib in ./venv3/lib/python3.6/site-packages (from SMPyBandits) (0.13.0)
Requirement already satisfied: scipy>0.9 in ./venv3/lib/python3.6/site-packages (from SMPyBandits) (1.1.0)
Requirement already satisfied: ipython in ./venv3/lib/python3.6/site-packages (from watermark) (7.1.1)
Requirement already satisfied: kiwisolver>=1.0.1 in ./venv3/lib/python3.6/site-packages (from matplotlib>=2->SMPyBandits) (1.0.1)
Requirement already satisfied: cycler>=0.10 in ./venv3/lib/python3.6/site-packages (from matplotlib>=2->SMPyBandits) (0.10.0)
Requirement already satisfied: python-dateutil>=2.1 in ./venv3/lib/python3.6/site-packages (from matplotlib>=2->SMPyBandits) (2.7.5)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in ./venv3/lib/python3.6/site-packages (from matplotlib>=2->SMPyBandits) (2.3.0)
Requirement already satisfied: pandas>=0.15.2 in ./venv3/lib/python3.6/site-packages (from seaborn->SMPyBandits) (0.23.4)
Requirement already satisfied: pygments in ./venv3/lib/python3.6/site-packages (from ipython->watermark) (2.2.0)
Requirement already satisfied: pickleshare in ./venv3/lib/python3.6/site-packages (from ipython->watermark) (0.7.5)
Requirement already satisfied: pexpect; sys_platform != "win32" in ./venv3/lib/python3.6/site-packages (from ipython->watermark) (4.6.0)
Requirement already satisfied: jedi>=0.10 in ./venv3/lib/python3.6/site-packages (from ipython->watermark) (0.13.1)
Requirement already satisfied: traitlets>=4.2 in ./venv3/lib/python3.6/site-packages (from ipython->watermark) (4.3.2)
Requirement already satisfied: backcall in ./venv3/lib/python3.6/site-packages (from ipython->watermark) (0.1.0)
Requirement already satisfied: prompt-toolkit<2.1.0,>=2.0.0 in ./venv3/lib/python3.6/site-packages (from ipython->watermark) (2.0.7)
Requirement already satisfied: setuptools>=18.5 in ./venv3/lib/python3.6/site-packages (from ipython->watermark) (40.6.2)
Requirement already satisfied: decorator in ./venv3/lib/python3.6/site-packages (from ipython->watermark) (4.3.0)
Requirement already satisfied: six in ./venv3/lib/python3.6/site-packages (from cycler>=0.10->matplotlib>=2->SMPyBandits) (1.11.0)
Requirement already satisfied: pytz>=2011k in ./venv3/lib/python3.6/site-packages (from pandas>=0.15.2->seaborn->SMPyBandits) (2018.7)
Requirement already satisfied: ptyprocess>=0.5 in ./venv3/lib/python3.6/site-packages (from pexpect; sys_platform != "win32"->ipython->watermark) (0.6.0)
Requirement already satisfied: parso>=0.3.0 in ./venv3/lib/python3.6/site-packages (from jedi>=0.10->ipython->watermark) (0.3.1)
Requirement already satisfied: ipython-genutils in ./venv3/lib/python3.6/site-packages (from traitlets>=4.2->ipython->watermark) (0.2.0)
Requirement already satisfied: wcwidth in ./venv3/lib/python3.6/site-packages (from prompt-toolkit<2.1.0,>=2.0.0->ipython->watermark) (0.1.7)
Installing collected packages: watermark
Successfully installed watermark-1.7.0
Info: Using the Jupyter notebook version of the tqdm() decorator, tqdm_notebook() ...
Lilian Besson
CPython 3.6.6
IPython 7.1.1
SMPyBandits 0.9.4
compiler : GCC 8.0.1 20180414 (experimental) [trunk revision 259383
system : Linux
release : 4.15.0-38-generic
machine : x86_64
processor : x86_64
CPU cores : 4
interpreter: 64bit
[3]:
# Local imports
from SMPyBandits.Environment import Evaluator, tqdm
We also need arms, for instance Bernoulli-distributed arm:
[4]:
# Import arms
from SMPyBandits.Arms import Bernoulli
And finally we need some single-player Reinforcement Learning algorithms:
[5]:
# Import algorithms
from SMPyBandits.Policies import *
For instance, this imported the `UCB algorithm <https://en.wikipedia.org/wiki/Multi-armed_bandit#Bandit_strategies>`__ is the UCBalpha class:
[6]:
# Just improving the ?? in Jupyter. Thanks to https://nbviewer.jupyter.org/gist/minrk/7715212
from __future__ import print_function
from IPython.core import page
def myprint(s):
try:
print(s['text/plain'])
except (KeyError, TypeError):
print(s)
page.page = myprint
[7]:
UCBalpha?
Init signature: UCBalpha(nbArms, alpha=4, lower=0.0, amplitude=1.0)
Docstring:
The UCB1 (UCB-alpha) index policy, modified to take a random permutation order for the initial exploration of each arm (reduce collisions in the multi-players setting).
Reference: [Auer et al. 02].
Init docstring:
New generic index policy.
- nbArms: the number of arms,
- lower, amplitude: lower value and known amplitude of the rewards.
File: /tmp/SMPyBandits/notebooks/venv3/lib/python3.6/site-packages/SMPyBandits/Policies/UCBalpha.py
Type: type
With more details, here the code:
[8]:
UCBalpha??
Init signature: UCBalpha(nbArms, alpha=4, lower=0.0, amplitude=1.0)
Source:
class UCBalpha(UCB):
""" The UCB1 (UCB-alpha) index policy, modified to take a random permutation order for the initial exploration of each arm (reduce collisions in the multi-players setting).
Reference: [Auer et al. 02].
"""
def __init__(self, nbArms, alpha=ALPHA, lower=0., amplitude=1.):
super(UCBalpha, self).__init__(nbArms, lower=lower, amplitude=amplitude)
assert alpha >= 0, "Error: the alpha parameter for UCBalpha class has to be >= 0." # DEBUG
self.alpha = alpha #: Parameter alpha
def __str__(self):
return r"UCB($\alpha={:.3g}$)".format(self.alpha)
def computeIndex(self, arm):
r""" Compute the current index, at time t and after :math:`N_k(t)` pulls of arm k:
.. math:: I_k(t) = \frac{X_k(t)}{N_k(t)} + \sqrt{\frac{\alpha \log(t)}{2 N_k(t)}}.
"""
if self.pulls[arm] < 1:
return float('+inf')
else:
return (self.rewards[arm] / self.pulls[arm]) + sqrt((self.alpha * log(self.t)) / (2 * self.pulls[arm]))
def computeAllIndex(self):
""" Compute the current indexes for all arms, in a vectorized manner."""
indexes = (self.rewards / self.pulls) + np.sqrt((self.alpha * np.log(self.t)) / (2 * self.pulls))
indexes[self.pulls < 1] = float('+inf')
self.index[:] = indexes
File: /tmp/SMPyBandits/notebooks/venv3/lib/python3.6/site-packages/SMPyBandits/Policies/UCBalpha.py
Type: type
Creating the problem¶
Parameters for the simulation¶
\(T = 10000\) is the time horizon,
\(N = 10\) is the number of repetitions,
N_JOBS = 4is the number of cores used to parallelize the code.
[9]:
HORIZON = 10000
REPETITIONS = 10
N_JOBS = 1
Some MAB problem with Bernoulli arms¶
We consider in this example \(3\) problems, with Bernoulli arms, of different means.
[10]:
ENVIRONMENTS = [ # 1) Bernoulli arms
{ # A very easy problem, but it is used in a lot of articles
"arm_type": Bernoulli,
"params": [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
},
{ # An other problem, best arm = last, with three groups: very bad arms (0.01, 0.02), middle arms (0.3 - 0.6) and very good arms (0.78, 0.8, 0.82)
"arm_type": Bernoulli,
"params": [0.01, 0.02, 0.3, 0.4, 0.5, 0.6, 0.795, 0.8, 0.805]
},
{ # A very hard problem, as used in [Cappé et al, 2012]
"arm_type": Bernoulli,
"params": [0.01, 0.01, 0.01, 0.02, 0.02, 0.02, 0.05, 0.05, 0.1]
},
]
Some RL algorithms¶
We compare Thompson Sampling against \(\mathrm{UCB}_1\), and \(\mathrm{kl}-\mathrm{UCB}\).
[11]:
POLICIES = [
# --- UCB1 algorithm
{
"archtype": UCBalpha,
"params": {
"alpha": 1
}
},
{
"archtype": UCBalpha,
"params": {
"alpha": 0.5 # Smallest theoretically acceptable value
}
},
# --- Thompson algorithm
{
"archtype": Thompson,
"params": {}
},
# --- KL algorithms, here only klUCB
{
"archtype": klUCB,
"params": {}
},
# --- BayesUCB algorithm
{
"archtype": BayesUCB,
"params": {}
},
]
Complete configuration for the problem:
[12]:
configuration = {
# --- Duration of the experiment
"horizon": HORIZON,
# --- Number of repetition of the experiment (to have an average)
"repetitions": REPETITIONS,
# --- Parameters for the use of joblib.Parallel
"n_jobs": N_JOBS, # = nb of CPU cores
"verbosity": 6, # Max joblib verbosity
# --- Arms
"environment": ENVIRONMENTS,
# --- Algorithms
"policies": POLICIES,
}
configuration
[12]:
{'horizon': 10000,
'repetitions': 10,
'n_jobs': 1,
'verbosity': 6,
'environment': [{'arm_type': SMPyBandits.Arms.Bernoulli.Bernoulli,
'params': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]},
{'arm_type': SMPyBandits.Arms.Bernoulli.Bernoulli,
'params': [0.01, 0.02, 0.3, 0.4, 0.5, 0.6, 0.795, 0.8, 0.805]},
{'arm_type': SMPyBandits.Arms.Bernoulli.Bernoulli,
'params': [0.01, 0.01, 0.01, 0.02, 0.02, 0.02, 0.05, 0.05, 0.1]}],
'policies': [{'archtype': SMPyBandits.Policies.UCBalpha.UCBalpha,
'params': {'alpha': 1}},
{'archtype': SMPyBandits.Policies.UCBalpha.UCBalpha,
'params': {'alpha': 0.5}},
{'archtype': SMPyBandits.Policies.Thompson.Thompson, 'params': {}},
{'archtype': SMPyBandits.Policies.klUCB.klUCB, 'params': {}},
{'archtype': SMPyBandits.Policies.BayesUCB.BayesUCB, 'params': {}}]}
Creating the Evaluator object¶
[13]:
evaluation = Evaluator(configuration)
Number of policies in this comparison: 5
Time horizon: 10000
Number of repetitions: 10
Sampling rate for plotting, delta_t_plot: 1
Number of jobs for parallelization: 1
Using this dictionary to create a new environment:
{'arm_type': <class 'SMPyBandits.Arms.Bernoulli.Bernoulli'>, 'params': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]}
Creating a new MAB problem ...
Reading arms of this MAB problem from a dictionnary 'configuration' = {'arm_type': <class 'SMPyBandits.Arms.Bernoulli.Bernoulli'>, 'params': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]} ...
- with 'arm_type' = <class 'SMPyBandits.Arms.Bernoulli.Bernoulli'>
- with 'params' = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
- with 'arms' = [B(0.1), B(0.2), B(0.3), B(0.4), B(0.5), B(0.6), B(0.7), B(0.8), B(0.9)]
- with 'means' = [0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]
- with 'nbArms' = 9
- with 'maxArm' = 0.9
- with 'minArm' = 0.1
This MAB problem has:
- a [Lai & Robbins] complexity constant C(mu) = 7.52 ...
- a Optimal Arm Identification factor H_OI(mu) = 48.89% ...
- with 'arms' represented as: $[B(0.1), B(0.2), B(0.3), B(0.4), B(0.5), B(0.6), B(0.7), B(0.8), B(0.9)^*]$
Using this dictionary to create a new environment:
{'arm_type': <class 'SMPyBandits.Arms.Bernoulli.Bernoulli'>, 'params': [0.01, 0.02, 0.3, 0.4, 0.5, 0.6, 0.795, 0.8, 0.805]}
Creating a new MAB problem ...
Reading arms of this MAB problem from a dictionnary 'configuration' = {'arm_type': <class 'SMPyBandits.Arms.Bernoulli.Bernoulli'>, 'params': [0.01, 0.02, 0.3, 0.4, 0.5, 0.6, 0.795, 0.8, 0.805]} ...
- with 'arm_type' = <class 'SMPyBandits.Arms.Bernoulli.Bernoulli'>
- with 'params' = [0.01, 0.02, 0.3, 0.4, 0.5, 0.6, 0.795, 0.8, 0.805]
- with 'arms' = [B(0.01), B(0.02), B(0.3), B(0.4), B(0.5), B(0.6), B(0.795), B(0.8), B(0.805)]
- with 'means' = [0.01 0.02 0.3 0.4 0.5 0.6 0.795 0.8 0.805]
- with 'nbArms' = 9
- with 'maxArm' = 0.805
- with 'minArm' = 0.01
This MAB problem has:
- a [Lai & Robbins] complexity constant C(mu) = 101 ...
- a Optimal Arm Identification factor H_OI(mu) = 55.39% ...
- with 'arms' represented as: $[B(0.01), B(0.02), B(0.3), B(0.4), B(0.5), B(0.6), B(0.795), B(0.8), B(0.805)^*]$
Using this dictionary to create a new environment:
{'arm_type': <class 'SMPyBandits.Arms.Bernoulli.Bernoulli'>, 'params': [0.01, 0.01, 0.01, 0.02, 0.02, 0.02, 0.05, 0.05, 0.1]}
Creating a new MAB problem ...
Reading arms of this MAB problem from a dictionnary 'configuration' = {'arm_type': <class 'SMPyBandits.Arms.Bernoulli.Bernoulli'>, 'params': [0.01, 0.01, 0.01, 0.02, 0.02, 0.02, 0.05, 0.05, 0.1]} ...
- with 'arm_type' = <class 'SMPyBandits.Arms.Bernoulli.Bernoulli'>
- with 'params' = [0.01, 0.01, 0.01, 0.02, 0.02, 0.02, 0.05, 0.05, 0.1]
- with 'arms' = [B(0.01), B(0.01), B(0.01), B(0.02), B(0.02), B(0.02), B(0.05), B(0.05), B(0.1)]
- with 'means' = [0.01 0.01 0.01 0.02 0.02 0.02 0.05 0.05 0.1 ]
- with 'nbArms' = 9
- with 'maxArm' = 0.1
- with 'minArm' = 0.01
This MAB problem has:
- a [Lai & Robbins] complexity constant C(mu) = 14.5 ...
- a Optimal Arm Identification factor H_OI(mu) = 82.11% ...
- with 'arms' represented as: $[B(0.01), B(0.01), B(0.01), B(0.02), B(0.02), B(0.02), B(0.05), B(0.05), B(0.1)^*]$
Number of environments to try: 3
Solving the problem¶
Now we can simulate all the \(3\) environments. That part can take some time.
[14]:
for envId, env in tqdm(enumerate(evaluation.envs), desc="Problems"):
# Evaluate just that env
evaluation.startOneEnv(envId, env)
Evaluating environment: MAB(nbArms: 9, arms: [B(0.1), B(0.2), B(0.3), B(0.4), B(0.5), B(0.6), B(0.7), B(0.8), B(0.9)], minArm: 0.1, maxArm: 0.9)
- Adding policy #1 = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 1}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][0]' = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 1}} ...
- Adding policy #2 = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 0.5}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][1]' = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 0.5}} ...
- Adding policy #3 = {'archtype': <class 'SMPyBandits.Policies.Thompson.Thompson'>, 'params': {}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][2]' = {'archtype': <class 'SMPyBandits.Policies.Thompson.Thompson'>, 'params': {}} ...
- Adding policy #4 = {'archtype': <class 'SMPyBandits.Policies.klUCB.klUCB'>, 'params': {}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][3]' = {'archtype': <class 'SMPyBandits.Policies.klUCB.klUCB'>, 'params': {}} ...
- Adding policy #5 = {'archtype': <class 'SMPyBandits.Policies.BayesUCB.BayesUCB'>, 'params': {}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][4]' = {'archtype': <class 'SMPyBandits.Policies.BayesUCB.BayesUCB'>, 'params': {}} ...
- Evaluating policy #1/5: UCB($\alpha=1$) ...
Estimated order by the policy UCB($\alpha=1$) after 10000 steps: [0 4 2 5 3 6 7 1 8] ...
==> Optimal arm identification: 100.00% (relative success)...
==> Mean distance from optimal ordering: 66.05% (relative success)...
- Evaluating policy #2/5: UCB($\alpha=0.5$) ...
Estimated order by the policy UCB($\alpha=0.5$) after 10000 steps: [0 4 2 5 7 1 3 6 8] ...
==> Optimal arm identification: 100.00% (relative success)...
==> Mean distance from optimal ordering: 58.02% (relative success)...
- Evaluating policy #3/5: Thompson ...
Estimated order by the policy Thompson after 10000 steps: [2 1 0 6 4 3 5 7 8] ...
==> Optimal arm identification: 100.00% (relative success)...
==> Mean distance from optimal ordering: 59.88% (relative success)...
- Evaluating policy #4/5: kl-UCB ...
Estimated order by the policy kl-UCB after 10000 steps: [4 3 0 1 2 5 6 8 7] ...
==> Optimal arm identification: 88.89% (relative success)...
==> Mean distance from optimal ordering: 66.05% (relative success)...
- Evaluating policy #5/5: BayesUCB ...
Estimated order by the policy BayesUCB after 10000 steps: [1 4 2 0 3 6 5 7 8] ...
==> Optimal arm identification: 100.00% (relative success)...
==> Mean distance from optimal ordering: 65.43% (relative success)...
Evaluating environment: MAB(nbArms: 9, arms: [B(0.01), B(0.02), B(0.3), B(0.4), B(0.5), B(0.6), B(0.795), B(0.8), B(0.805)], minArm: 0.01, maxArm: 0.805)
- Adding policy #1 = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 1}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][0]' = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 1}} ...
- Adding policy #2 = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 0.5}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][1]' = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 0.5}} ...
- Adding policy #3 = {'archtype': <class 'SMPyBandits.Policies.Thompson.Thompson'>, 'params': {}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][2]' = {'archtype': <class 'SMPyBandits.Policies.Thompson.Thompson'>, 'params': {}} ...
- Adding policy #4 = {'archtype': <class 'SMPyBandits.Policies.klUCB.klUCB'>, 'params': {}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][3]' = {'archtype': <class 'SMPyBandits.Policies.klUCB.klUCB'>, 'params': {}} ...
- Adding policy #5 = {'archtype': <class 'SMPyBandits.Policies.BayesUCB.BayesUCB'>, 'params': {}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][4]' = {'archtype': <class 'SMPyBandits.Policies.BayesUCB.BayesUCB'>, 'params': {}} ...
- Evaluating policy #1/5: UCB($\alpha=1$) ...
Estimated order by the policy UCB($\alpha=1$) after 10000 steps: [0 1 2 3 4 5 6 8 7] ...
==> Optimal arm identification: 99.38% (relative success)...
==> Mean distance from optimal ordering: 91.98% (relative success)...
- Evaluating policy #2/5: UCB($\alpha=0.5$) ...
Estimated order by the policy UCB($\alpha=0.5$) after 10000 steps: [0 1 2 3 4 5 6 7 8] ...
==> Optimal arm identification: 100.00% (relative success)...
==> Mean distance from optimal ordering: 100.00% (relative success)...
- Evaluating policy #3/5: Thompson ...
Estimated order by the policy Thompson after 10000 steps: [0 1 5 2 4 3 7 8 6] ...
==> Optimal arm identification: 98.76% (relative success)...
==> Mean distance from optimal ordering: 65.43% (relative success)...
- Evaluating policy #4/5: kl-UCB ...
Estimated order by the policy kl-UCB after 10000 steps: [0 1 3 2 5 4 8 6 7] ...
==> Optimal arm identification: 99.38% (relative success)...
==> Mean distance from optimal ordering: 73.46% (relative success)...
- Evaluating policy #5/5: BayesUCB ...
Estimated order by the policy BayesUCB after 10000 steps: [0 1 2 3 4 5 7 8 6] ...
==> Optimal arm identification: 98.76% (relative success)...
==> Mean distance from optimal ordering: 89.51% (relative success)...
Evaluating environment: MAB(nbArms: 9, arms: [B(0.01), B(0.01), B(0.01), B(0.02), B(0.02), B(0.02), B(0.05), B(0.05), B(0.1)], minArm: 0.01, maxArm: 0.1)
- Adding policy #1 = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 1}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][0]' = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 1}} ...
- Adding policy #2 = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 0.5}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][1]' = {'archtype': <class 'SMPyBandits.Policies.UCBalpha.UCBalpha'>, 'params': {'alpha': 0.5}} ...
- Adding policy #3 = {'archtype': <class 'SMPyBandits.Policies.Thompson.Thompson'>, 'params': {}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][2]' = {'archtype': <class 'SMPyBandits.Policies.Thompson.Thompson'>, 'params': {}} ...
- Adding policy #4 = {'archtype': <class 'SMPyBandits.Policies.klUCB.klUCB'>, 'params': {}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][3]' = {'archtype': <class 'SMPyBandits.Policies.klUCB.klUCB'>, 'params': {}} ...
- Adding policy #5 = {'archtype': <class 'SMPyBandits.Policies.BayesUCB.BayesUCB'>, 'params': {}} ...
Creating this policy from a dictionnary 'self.cfg['policies'][4]' = {'archtype': <class 'SMPyBandits.Policies.BayesUCB.BayesUCB'>, 'params': {}} ...
- Evaluating policy #1/5: UCB($\alpha=1$) ...
Estimated order by the policy UCB($\alpha=1$) after 10000 steps: [6 7 3 0 2 4 1 5 8] ...
==> Optimal arm identification: 100.00% (relative success)...
==> Mean distance from optimal ordering: 34.57% (relative success)...
- Evaluating policy #2/5: UCB($\alpha=0.5$) ...
Estimated order by the policy UCB($\alpha=0.5$) after 10000 steps: [2 3 5 6 0 7 4 1 8] ...
==> Optimal arm identification: 100.00% (relative success)...
==> Mean distance from optimal ordering: 53.70% (relative success)...
- Evaluating policy #3/5: Thompson ...
Estimated order by the policy Thompson after 10000 steps: [2 1 3 4 5 0 7 6 8] ...
==> Optimal arm identification: 100.00% (relative success)...
==> Mean distance from optimal ordering: 68.52% (relative success)...
- Evaluating policy #4/5: kl-UCB ...
Estimated order by the policy kl-UCB after 10000 steps: [0 4 7 2 1 5 6 3 8] ...
==> Optimal arm identification: 100.00% (relative success)...
==> Mean distance from optimal ordering: 58.02% (relative success)...
- Evaluating policy #5/5: BayesUCB ...
Estimated order by the policy BayesUCB after 10000 steps: [5 6 4 3 7 0 1 2 8] ...
==> Optimal arm identification: 100.00% (relative success)...
==> Mean distance from optimal ordering: 35.19% (relative success)...
Plotting the results¶
And finally, visualize them, with the plotting method of a Evaluator object:
[15]:
def plotAll(evaluation, envId):
evaluation.printFinalRanking(envId)
evaluation.plotRegrets(envId)
evaluation.plotRegrets(envId, semilogx=True)
evaluation.plotRegrets(envId, meanReward=True)
evaluation.plotBestArmPulls(envId)
[16]:
evaluation.nb_break_points
[16]:
0
[20]:
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12.4, 7)
First problem¶
\([B(0.1), B(0.2), B(0.3), B(0.4), B(0.5), B(0.6), B(0.7), B(0.8), B(0.9)]\)
[21]:
_ = plotAll(evaluation, 0)
Final ranking for this environment #0 :
- Policy 'Thompson' was ranked 1 / 5 for this simulation (last regret = 33.2).
- Policy 'UCB($\alpha=0.5$)' was ranked 2 / 5 for this simulation (last regret = 49.52).
- Policy 'kl-UCB' was ranked 3 / 5 for this simulation (last regret = 51.36).
- Policy 'BayesUCB' was ranked 4 / 5 for this simulation (last regret = 58.74).
- Policy 'UCB($\alpha=1$)' was ranked 5 / 5 for this simulation (last regret = 98.04).
This MAB problem has:
- a [Lai & Robbins] complexity constant C(mu) = 7.52 for 1-player problem...
- a Optimal Arm Identification factor H_OI(mu) = 48.89% ...
Warning: forcing to use putatright = False because there is 6 items in the legend.
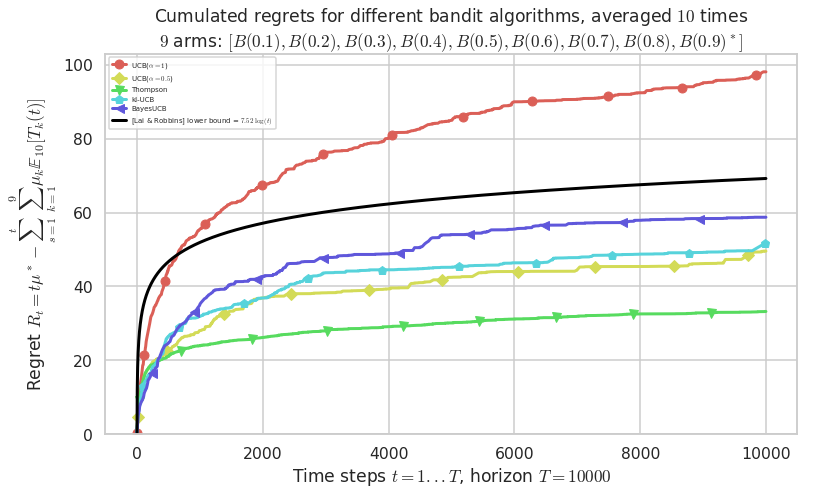
Warning: forcing to use putatright = False because there is 6 items in the legend.
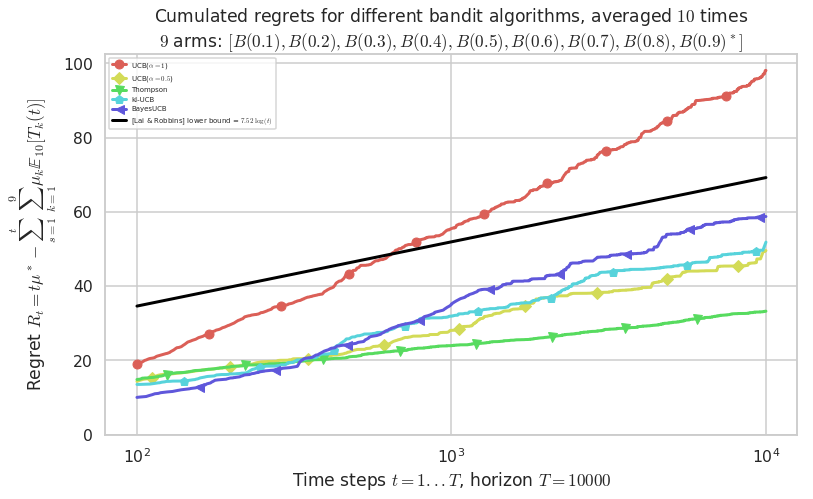
This MAB problem has:
- a [Lai & Robbins] complexity constant C(mu) = 7.52 for 1-player problem...
- a Optimal Arm Identification factor H_OI(mu) = 48.89% ...
Warning: forcing to use putatright = False because there is 6 items in the legend.
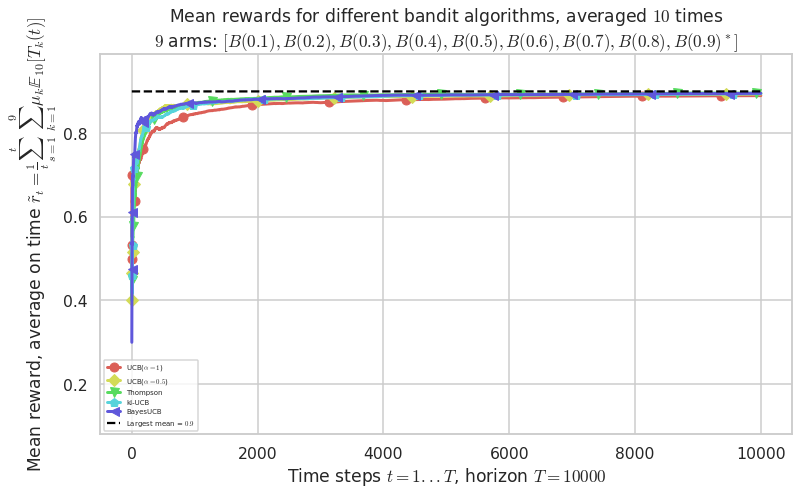
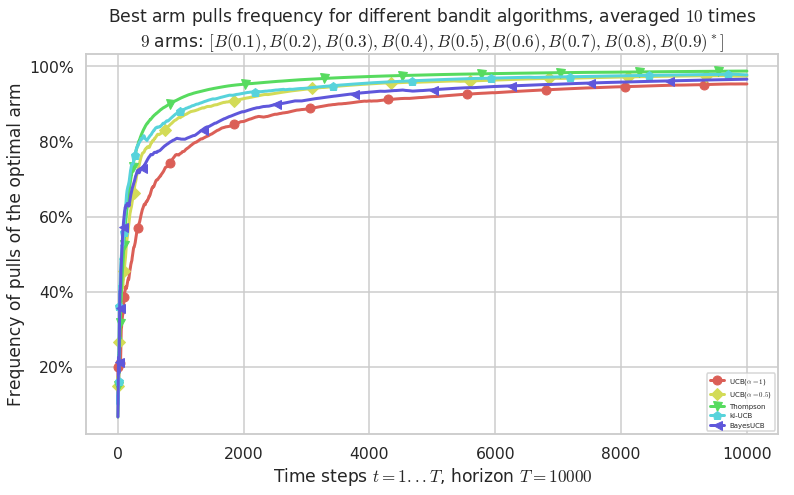
Warning: forcing to use putatright = False because there is 5 items in the legend.
Second problem¶
\([B(0.01), B(0.02), B(0.3), B(0.4), B(0.5), B(0.6), B(0.795), B(0.8), B(0.805)]\)
[22]:
plotAll(evaluation, 1)
Final ranking for this environment #1 :
- Policy 'UCB($\alpha=0.5$)' was ranked 1 / 5 for this simulation (last regret = 65.017).
- Policy 'BayesUCB' was ranked 2 / 5 for this simulation (last regret = 70.413).
- Policy 'Thompson' was ranked 3 / 5 for this simulation (last regret = 83.188).
- Policy 'kl-UCB' was ranked 4 / 5 for this simulation (last regret = 84.505).
- Policy 'UCB($\alpha=1$)' was ranked 5 / 5 for this simulation (last regret = 96.174).
This MAB problem has:
- a [Lai & Robbins] complexity constant C(mu) = 101 for 1-player problem...
- a Optimal Arm Identification factor H_OI(mu) = 55.39% ...
Warning: forcing to use putatright = False because there is 6 items in the legend.
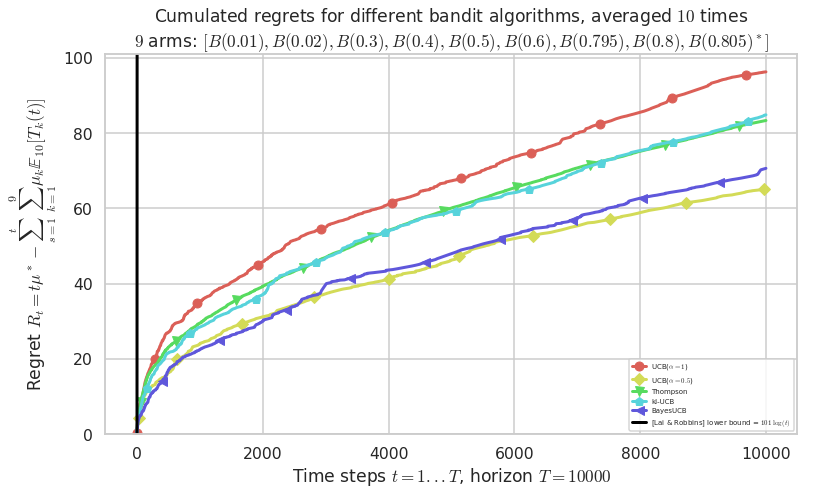
Warning: forcing to use putatright = False because there is 6 items in the legend.
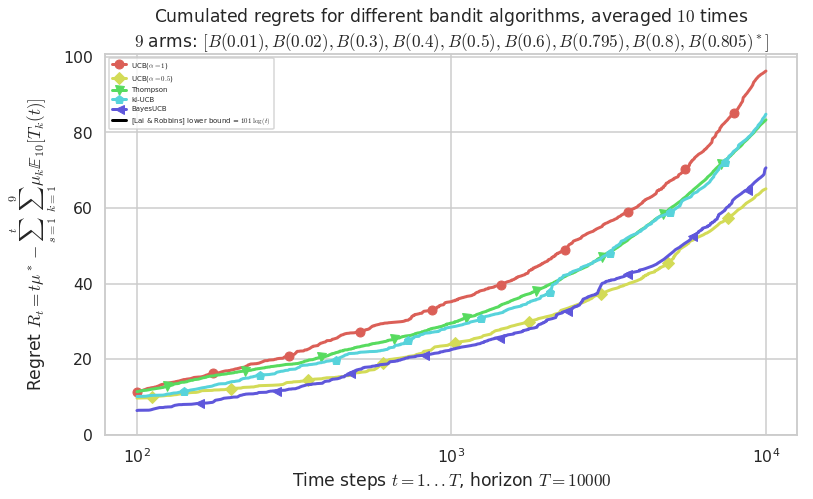
This MAB problem has:
- a [Lai & Robbins] complexity constant C(mu) = 101 for 1-player problem...
- a Optimal Arm Identification factor H_OI(mu) = 55.39% ...
Warning: forcing to use putatright = False because there is 6 items in the legend.
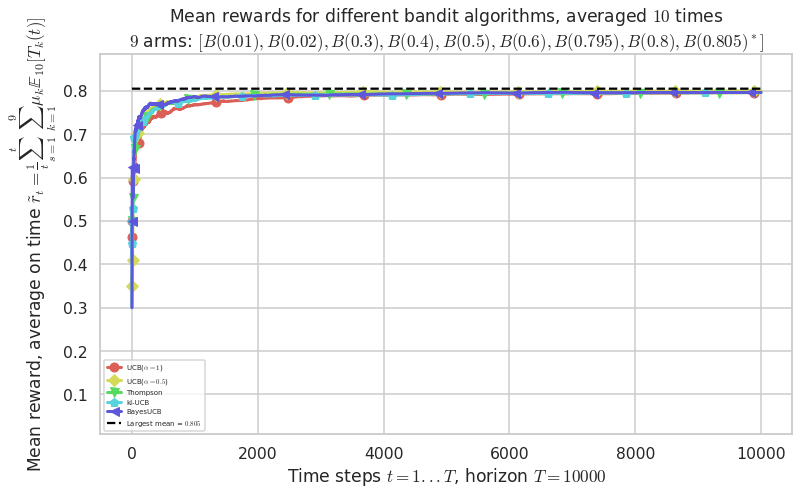
Warning: forcing to use putatright = False because there is 5 items in the legend.
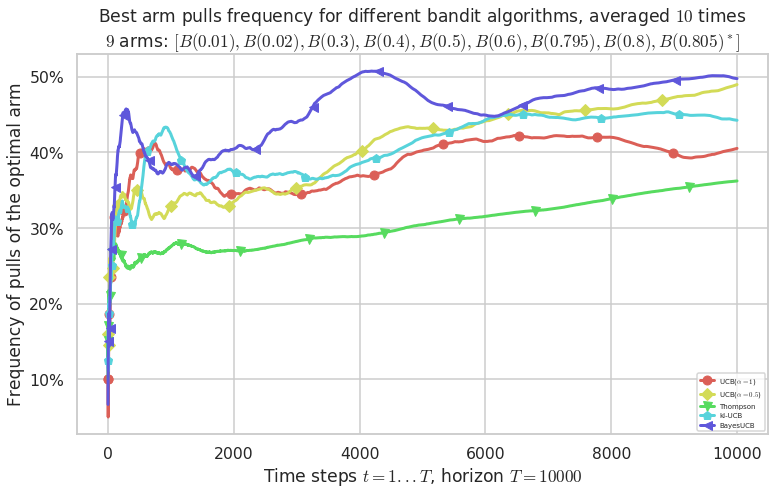
Third problem¶
\([B(0.01), B(0.01), B(0.01), B(0.02), B(0.02), B(0.02), B(0.05), B(0.05), B(0.1)]\)
[23]:
plotAll(evaluation, 2)
Final ranking for this environment #2 :
- Policy 'Thompson' was ranked 1 / 5 for this simulation (last regret = 69.227).
- Policy 'BayesUCB' was ranked 2 / 5 for this simulation (last regret = 84.888).
- Policy 'kl-UCB' was ranked 3 / 5 for this simulation (last regret = 94.7).
- Policy 'UCB($\alpha=0.5$)' was ranked 4 / 5 for this simulation (last regret = 162.35).
- Policy 'UCB($\alpha=1$)' was ranked 5 / 5 for this simulation (last regret = 282.57).
This MAB problem has:
- a [Lai & Robbins] complexity constant C(mu) = 14.5 for 1-player problem...
- a Optimal Arm Identification factor H_OI(mu) = 82.11% ...
Warning: forcing to use putatright = False because there is 6 items in the legend.
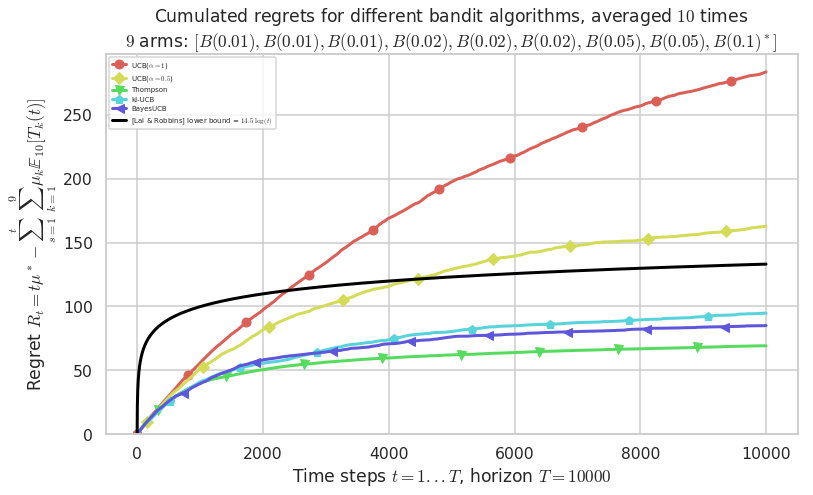
Warning: forcing to use putatright = False because there is 6 items in the legend.
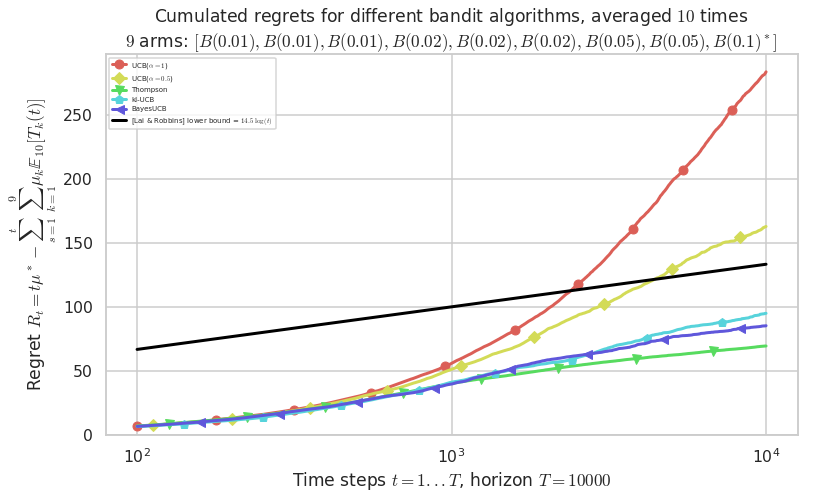
This MAB problem has:
- a [Lai & Robbins] complexity constant C(mu) = 14.5 for 1-player problem...
- a Optimal Arm Identification factor H_OI(mu) = 82.11% ...
Warning: forcing to use putatright = False because there is 6 items in the legend.
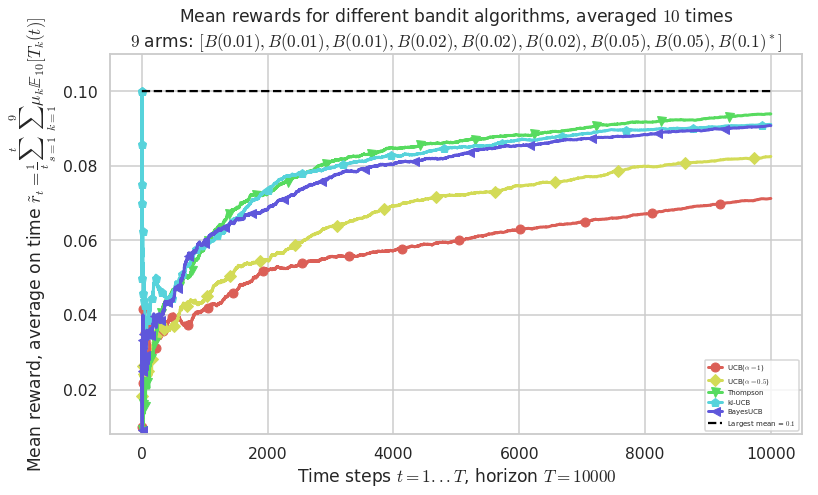
Warning: forcing to use putatright = False because there is 5 items in the legend.
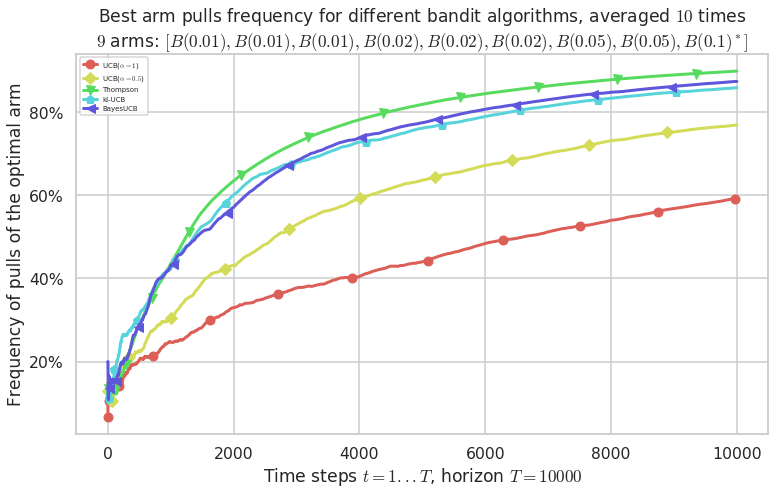
That’s it for this demo!